FaceSwap换脸使用与学习笔记
FaceSwap换脸使用与学习笔记
原理
个人理解,若有错误请指出,谢谢
该程序使用AutoEncoder进行图片的处理和学习
分别输入AB俩个人的图片
输入同一个编码器(编码器的作用把图片进行一定的混淆和加干扰),然后分别对应A_out,B_out俩个输出器,一直长时间进行的训练,直到输出器能够在
存在干扰的情况下输出正常的图片,其中的loss就是差异比率,自写的loss算法进行对比图片差异,训练的过程本质就是降低loss的比率,
等训练到一定程度,我们讲A的图片通过B_out进行输出,这个时候B_out这个输出器以为我们输入的是一张存在干扰的B的图片,然后就会把脸部修复成B的样子,从这里实现了换脸,
不同的训练模型对应的就是
只换脸部 同时输入脸部和去掉脸部的头部信息,输出图片
换头部(SAE)
就是输入整个头部信息在等待输出
实际过程应该是
AB使用同一个encoder(即相同的混淆器),然后分别使用各自的Decoder进行解码,然后在通过自定义的Loss取得差异度,然后不断的进行降低差异度的操作,在一定程度的时候将B进行encoder之后调用A的Decoder进行解码,这个时候DecoderA以为输入的是A的脸,然后进行了一定的修复还原成A的脸,达到了换脸的目的。
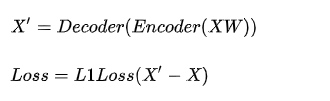
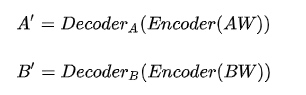
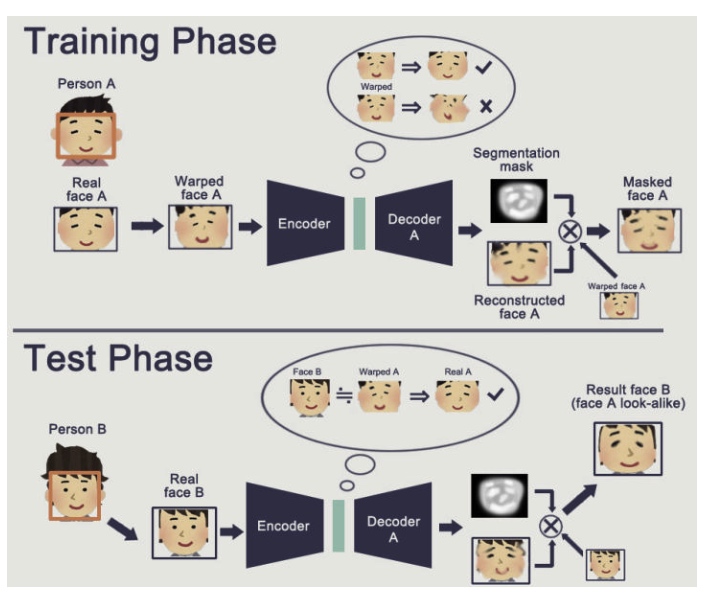
注:图片来源知乎 https://zhuanlan.zhihu.com/p/34042498
安装方法
这里使用ubuntu 18.04作为系统环境
首先安装Nvida的驱动
sudo apt-get install software-properties-common
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo ubuntu-drivers autoinstall
apt install docker.io
然后使用docker安装FaceSwap
1 首先安装
https://github.com/NVIDIA/nvidia-docker
# Add the package repositories
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker
apt install nvidia-docker22 安装Docker和环境
docker build -t deepfakes-gpu -f Dockerfile.gpu . #如果是cpu则用cpu的file
3 启用
无GUI模式
nvidia-docker run --rm -it -p 8888:8888 \
--hostname faceswap-gpu --name faceswap-gpu \
-v /root/faceswap:/srv \
deepfakes-gpu开启GUI模式(需要装桌面环境)
nvidia-docker run -p 8888:8888 \
--hostname faceswap-gpu --name faceswap-gpu \
-v /root/faceswap:/srv \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-e DISPLAY=unix$DISPLAY \
-e AUDIO_GID=`getent group audio | cut -d: -f3` \
-e VIDEO_GID=`getent group video | cut -d: -f3` \
-e GID=`id -g` \
-e UID=`id -u` \
deepfakes-gpu
使用方法
首先需要准备俩个视频,最好都是正面的人脸视频,无干扰,我这里采用郭德纲和马云的俩个视频,分别作为AB进行输入
基本都是正面无其他人物,
1 提取人像
#表示从guo.mp4中提取人像输出目录到/out/guo中
docker exec -it faceswap-gpu python /srv/faceswap.py extract -i /srv/video/guo.mp4 -o /srv/video/out/guo/
#表示从ma.mp4中提取人像输出目录到/out/ma中
docker exec -it faceswap-gpu python /srv/faceswap.py extract -i /srv/video/ma.mp4 -o /srv/video/out/ma/2 开始训练
这里要注入,A和B的顺序,表示将B的脸训练到A上,最终的效果也就是把马云的脸换到郭德纲身上
这个指令是只替换脸部,不包括眉毛,下巴脑门等,如果需要整个脸部替换需要用SAE方式进行学习
docker exec -it faceswap-gpu python /srv/faceswap.py train -A /srv/video/out/new/guo/ -B /srv/video/out/new/ma/ -m /srv/video/out/new/guo2ma/SAE模式,只需要加上参数 -t dfl-sae即可
docker exec -it faceswap-gpu python /srv/faceswap.py train -A /srv/video/out/t/ -B /srv/video/out/me/ -m /srv/video/out/t2me/ -t dfl-sae开始训练之后会看到这样的输出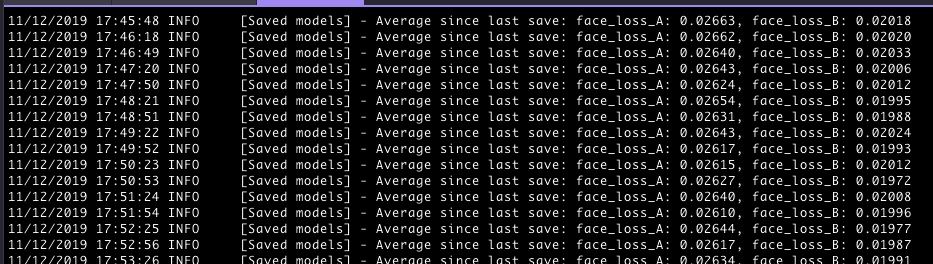
一般是从0.1x开始下降,一般下降到0.3一下就能看出模子了,训练的时间越长相似度就越高,我训练了大概12个小时,采用的Tesla P100 16G的显卡,效果大概如下


模型复用
修改SRC
模型复用最好的效果是保持A不变,修改B的图片,在之前马云和郭德纲的基础上,我将马云换成了赵丽颖,这样大概只训练了1-2个小时就出了非常好的结果,正常来说至少需要5-6个小时才能达到的效果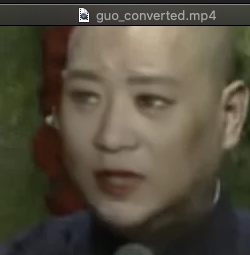
原始头像:
修改DST
现在我们换一下,将郭德纲改为B,即来源,将A换成赵丽颖,即将郭德纲的脸替换到赵丽颖的视频中,使用的模型基础为之前郭德纲和马云的底包,大概训练了1-2个小时左右的效果
可以发现非常模糊,原因有俩个
1 是郭德纲视频本身像素较低,而赵丽颖的像素较高导致了差异较大
2 我猜测可能是因为换了DST的原因,一般是推荐不换DST只换SRC即B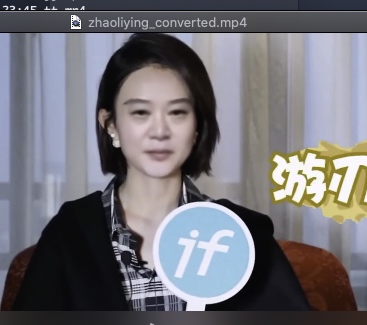
将DST改为SRC,SRC改为新面孔
我尝试使用郭德纲和马云的底包,将A改成郭德纲,B改为王思聪,最后训练的结果和马云郭德纲的结果几乎一样
docker exec -it faceswap-gpu python /srv/faceswap.py train -A /srv/video/out/new/guo/ -B /srv/video/out/new/wsc/ -m /srv/video/out/new/ww2guo/王思聪,郭德纲
马云,郭德纲
结论
最好的使用方法是AB保持不变,也就是专人专用,
其次的方案是A不变,可以修改B,即被贴脸的视频不变,修改贴上去的面孔。
在其次是B不变可以修改A,即贴脸的视频不变,修改被贴脸的视频
效果最差的是AB都修改
以上结论是使用相同底包,训练基本都是1-2个小时左右。