微信小程序开发之路 从0到2w用户
前言
之前写了一个小程序,映思圈,一个提供直接访问Instagram的网站,后来发现其实还是有一些用户需求的,就花了2-3天时间将网站写成了微信小程序。
目前过了3-4个月,没事推广推广,现在也有个2w多一点的用户了,分享一下过程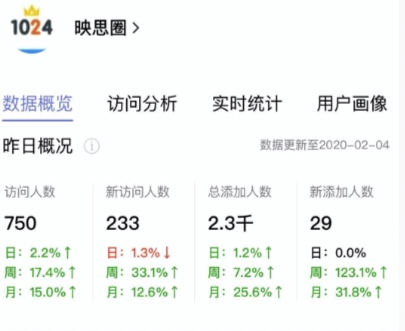
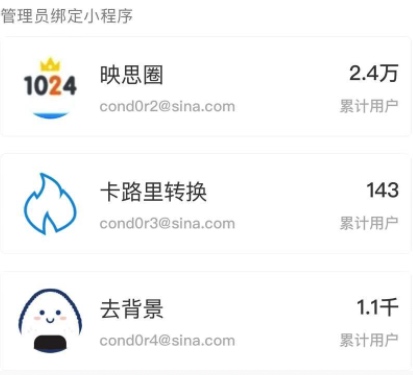
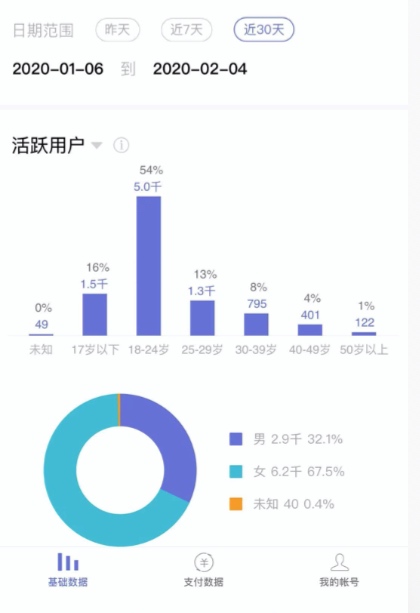
其采用的技术栈如下: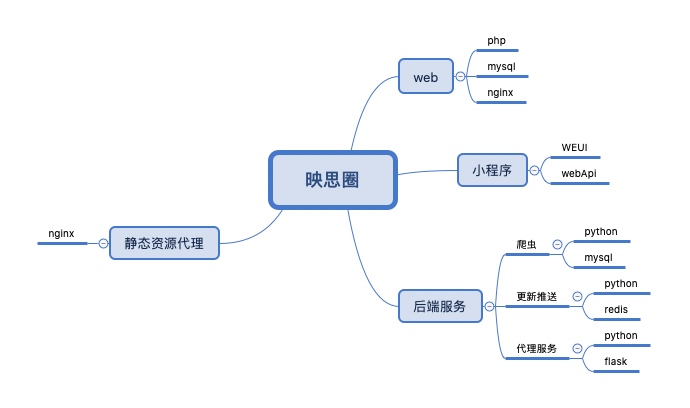
入门
说实话,第一次写微信小程序,前面也没接触过任何前端框架,都说微信小程序类似vue,看的也是一头雾水,因为前期的网站和爬虫写好了,所以后端其实没啥好赘述的,无非就是怎么抓包得到instagram的api,怎么获取用户资料和帖子,并且图片的存储什么的,没啥技术含量。
首先就是学习了一下小程序的结构和基本的语法,发现一个小程序基本的目录结构如下: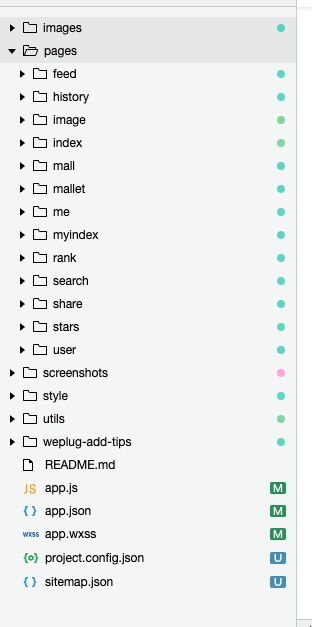
其中主要逻辑都是在pages目录下完成,有点类似MVC,代码与识图是分离的,一个完成的page包含四个文件 index.js,index.wxml,index.wxss,index.json
大概我们常用的文件/目录如下: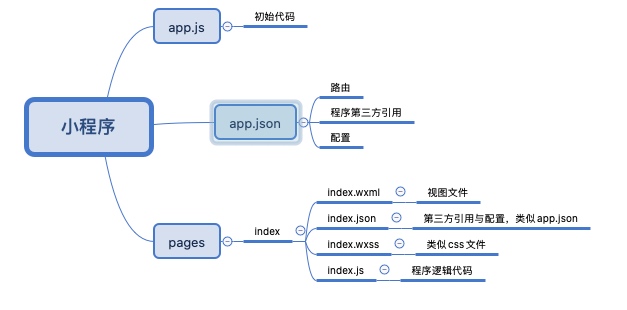
语法方面分俩块,一块是代码层面,一块是模版视图
语法
代码方面其实没太多好说的,因为他采用的是js进行开发,一个js的初始代码大概如下:
// pages/me/index.js
const app = getApp();
Page({
/**
* 页面的初始数据
*/
data: {
message: "none",
},
/**
* 生命周期函数--监听页面加载
*/
onLoad: function(options) {
},
/**
* 生命周期函数--监听页面初次渲染完成
*/
onReady: function() {
},
/**
* 生命周期函数--监听页面显示
*/
onShow: function() {
},
/**
* 生命周期函数--监听页面隐藏
*/
onHide: function() {
},
/**
* 生命周期函数--监听页面卸载
*/
onUnload: function() {
},
/**
* 页面相关事件处理函数--监听用户下拉动作
*/
onPullDownRefresh: function() {
},
/**
* 页面上拉触底事件的处理函数
*/
onReachBottom: function() {
},
/**
* 用户点击右上角分享
*/
onShareAppMessage: function() {
}
})所有的操作都会有一个触发事件,只要在触发事件里面写逻辑就可以了,然后一些常见的内置函数可以去看小程序的官方文档,基本都是在wx这个对象下面
关于模版的语法其实也比较容易上手
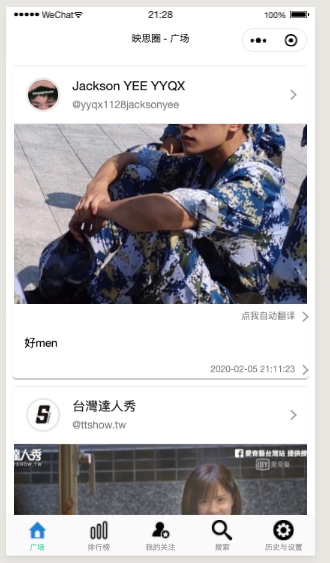
我的首页是这样的,一个卡片式的图文列表
代码就这么一些
先通过js的onload事件加载数据
/**
* 生命周期函数--监听页面加载
*/
onLoad: function(options) {
var openid = wx.getStorageSync('openid');
openid = openid ? openid : ''
var that = this
wx.request({
url: 'https://api.com/get_myfeed/' + openid,
success: res => {
wx.hideToast()
that.setData({
searchlist: res.data
})
}
})
},<view class="page">
<view class="page__bd">
<view class="weui-cells__title">我的关注</view>
//这里wx:for 就是一个for循环用来遍历数组的数据
<view class="weui-cells weui-cells_after-title" wx:for="{{searchlist}}" wx:key="pk">
<view class="weui-cell weui-cell_access" hover-class="weui-cell_active">
<navigator url="/pages/user/index?url={{item.uploader_id}}" class="weui-cell__hd">
<image src="{{item.profile_img}}" style="margin-right: 16px;vertical-align: middle;width:30px; height: 30px; float:left; border-radius: 50%; border: 3px solid #eee; overflow: hidden;"></image>
</navigator>
<navigator url="/pages/user/index?url={{item.uploader_id}}" class="weui-cell__bd">{{item.uploader_id}}</navigator>
<view class="weui-cell__ft weui-cell__ft_in-access" bindtap="onUnfeed" data-ownerid="{{item.owner_id}}">点我取关</view>
</view>
</view>
</view>
</view>其实还是非常简单的,然后最后写好的程序如下,其实还是非常简单的,前后开发小程序也就用了2天左右的时间,不得不说小程序真的非常容易上手。